

Original Transformer: Attention is All you Need was introduced in 2017 by Google for the purpose of translating sentences from a language to another using the attention mechanism, dispensing with recurrence and convolutions entirely. The architecture allows for significantly more parallelization and faster then traditional neural networks.
The idea of Transformers is simple, given an initial snippet of a sentence, the goal is to produce the word that cames next. Just like GPT(Generate Pre-trained Transformers) works, you ask questions and it predict what cames next which is the answer. The produced word is added to the initial sentence and run the process again until it came up with an entire answers.
Behind the scenes of GPTs
What is GPTs?
GPT stand for Generative Pre-trained Transforms is a type of Neural Network that uses Transformers to generate text, images, etc .
How deos it works ?
The input is broken up into tokens and each token can be a word or parts of the word ,the tokens are then encoded into a vectors that represent its meaning in high dimension space.
The vectors are being passed through Attention mechanism and MLPs(MulityLayer Preceptions) until we end up with bunch of vectors while the last one represent the next word .
Tokenization
As we all know, any machine learning models dont process raw data as it is like text, images and videos. The raw data is first transformed in a way that machines could understind which is numbers. In transformers that is called Tokenization.
Tokenization transform the input data such as text into words or subwords called tokens depend on the tokenization technique which bring us to the next part.
Types of Tokenization
Word-level tokenization
Word-level tokenization is where the input text splited into words, this technique is straighforward but it fails to handle words with multiple meanings.
Character-level tokenization
Character-level tokenization is a method where the text is splited into single characters or ponctuations, the downside of this approach is the vocabulary size become larger, forcing the model to have enormous embedding matrix.
Subword-level tokenization
This algorithm rely on dividing the text into word or subword, depends on the frequently used of the word, if the word is rarely used it should decompossed into meaningful subword and vise versa.
This appreoch is the most used one in LLM as it allows the model to have a reasonable vocabulary size and to capture meaningful context informations about the tokens .
Word Embedding
Words used to be represented in one-hot encoded vectors where each word has dimension equal to the vocabulary size with all 0 values except the position of that word with 1. This technique lacks from the sementic relationship between the words.
Word embedding is the process of turning the text into a dense vector in a multi-dimensional space (in GPT it is 12 288 dimensions) while the words with the same meaning tend to be closer .
The development of embedding has played crusial role in advancing NLP , machine translation and many more .
Word embedding is trained to predict dense vector with d(dimension) values that called weights that represent the meaning of a certain token, so if we predict the embedding of 50 257 tokens, we will have a vocabulary as a lockup table that can be used during the training of LLM i.e GPT3 .
There many types of word embeddings such as Word2Vec and GloVe(Global Vectors for Word representation) and BERT .
Word2Vec
Word2Vec made by the legend Tomáš Mikolov in 2013, it consists of two main models: Continious Bag of Word (CBOW) and Continious Skip-gram.
CBOW can be viewed as “fill in the blank”, it has 3 components, sliding window, targeted word, context words. Sliding window slides over the sentence with a fixed window size while skiping the targeted word which is the word that we want to predict*. Context words i*s the sentence we want to fill its blank. CBOW is trained to predict the target word accurately. The model wieghts are the words embedding vocabulary .
Continious Skip-gram on the other hand is the opposite of CBOW, it takes the target word as input and aims to predict the surronding context words. During the training, the model takes the target word as input and predict the probability distribution of each word in the vocabulary indicating the likelihood of each word being in the context words .
GloVe
GloVe is a word embedding model design to capture global statistical informations. The idea of GloVe is to construct two vectors wi and w~i of the word i where i is in the vocabulary .
Let V be the vocabulary size, Xi,j is the number of the times that the word j appears in th context of the word i over the entire corpus(sentences*).*
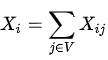
Where j is the index in V and Xi is the number of the words in the context of all instances of the word i (how many times the word i and j appears in the context of the word i over the entire corpuse of all the vocabulary), below is the a sample of the results .
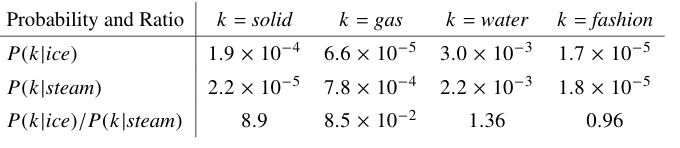
We can see that the probabilities tend to be far from 1 when they dont correlate, i.e if we take the first row of the word “ice”, the closest probability to 1 is where k=water because ice do correlate with the water but smaller for k=gas.
Note: To make use of the order of each token, in Transformers, the positional encoding is being added to the input embedding which then feed to the rest of the network..
Attention Architecture
Attention is another slice of transformer that help the embedding words understind each other by update its values to fit the current context of the entire sentence. Attention takes into consideration that the words dont have a constant meaning but rather it depend on the context.
Attention block takes each embedding token of i multiply it by the weights Wq, the result is a vector called Query denoted by Qi. The embedding tokens again are multiplied by the weights Wk, the result is a vector called Key denoted by Kj. Then the dot product is computed between each query and all keys, devided each by √dk where dk is the dimension of the keys, softmax an activation function is applied so the values are normalized between 0 and 1, the more they align, the closest value get to one. Now we want to update these softmax output so each token somehow influence the others, this is done by multiplying V with the softmax where V is the result of multiplying the initial embedding with Wv. We then sum all the values with the original embedding of all the tokens, this leaves us with more contextual rich meaning of each token*.*
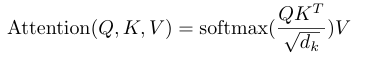
**The final output is what is called Self-Attention aka Intra-Attention because the computation of queries and keys happens between its tokens. However where there is two different tokens, that is called cross-attention. Cross-attention used in machine translation like two sentences in two different languages.
Masked Multi-Head Attention is employed sometime to make the prediction for position i can depend only on the known outputs at positions less then i. Meaning each token has to depend on the next tokens only .
You will notice that this entire attention happens a once, in that case that is single head attention. In case of many onces, that is what Multi-head attentions, each head attention is computed seperately but the final outputs are all concated and multiplyed with Wo resulting into a single attention layer which is just a slice of the transformers architecture .

Multi-Layer Perceptrons
This is the block that is reponsible for storing the facts about the worlds. Essentially it is just a multiplication of the weights added to the biases with the vectors that was produced by the attention block. At the end of each MLP, the original vectors are being added to the final outputs to draw the facts about the embedding tokens .
The residual connection is employed around each of the sub-layers (Attentions and MLPs) followed by ReLU activation function then the normalization layer.
These two blocks of Attentions and MLPs are being repeated many times and that is one of the many things that makes each LLM models different from each other which is the number of blocks each one has and why each one has differents number of parameters.
See figure below for the entire transformer architecture .
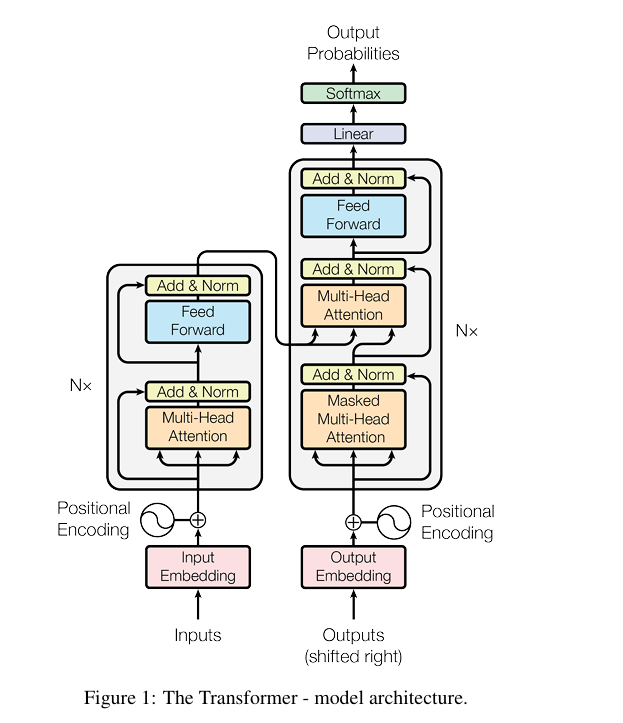
The left side is called encoder while the right side is the decoder. N=6 which is the number of identical layers.
Unembedding
Unembedding is where we take the last outputs from the transformers architecture and we try to decode in a way that we can get the actual meaning of it. For instance in LLM, we take the last matrix, we unembedding it so that we can get the prediction word. Unembedding is the opposite of the embedding, instead of encoding the words, it decode them by multiplying the last output in the transformers with the unembedding matrix denoted by Wu with dimension equal to the vocabulary size. The final output are being passed through softmax to create probability distribution of the logits (the outputs before softmax). The highest value indicates the index of the word in the vocabulary hence the predicted word
Transformers in Actions
Transformers have revolutionized artificial intelligence, powering many powerful models that we use in our day to day life such as ChatGPT, Midjourney, Dalle ,etc .
Transformers are widely used in NLP and Computer Vision, beating many traditional neural networks such as convolution and recurrent networks in many domains.
In natural language processing and computer vision, transformers had made significant impact across various domains such as machine translations, time series predictions, document summarization, named entity recognitions, speech to text, video understinding, text generations, code generations and image generations and so on.
At the time of this article, yesterday xAI have just launched its Grok 4, the smartest model in the world up to date which was built on the top of transformers. This leaves us with a question, can we see transformers powers the AGI in the future ? I guess we have to find out .
Credits:
Transformers, the tech behind LLMs | Deep Learning Chapter 5
https://www.ibm.com/think/topics/word-embeddings
Understanding Transformers Step by Step — Word Embeddings | by Deepanshusachdeva | Medium
https://huggingface.co/docs/transformers/en/tokenizer_summary
Preparing Text Data for Transformers: Tokenization, Mapping and Padding | by Ganesh Lokare | Medium