

In this article we will summeries everything in You Only Look Once: Unified, Real-Time Object Detection paper which is a state-of-the-art object detection that was introduced in 2016 . YOLOv1 is extremly fast and it can processes images in real-time at 45 frames per second . Another small version of the network, Fast YOLO processes 155 frames per second . YOLO makes more localization errors but is less likely to predict false positives on the background compare to other approachs .
Checkout this video for demo of YOLO
Current detection systems use complex pipeline that are slow and hard to optimize . The traditional methods use sliding window over the image and generate potential bounding boxes in an image and then run a classifier on these proposed boxes . Then refine the bounding boxes and eliminate duplicate detections . With this approach , each individual component must be trained seperately compared to YOLO. A single convolution network uses the image to predict multiple bounding boxes and class probabilities for those boxes.
Unified Detection
All the seperate components of object detection is unified into a single neural network . The network sees the entire image and predict each bounding box across all the classes simultaneously. This helps the network to understind the context and to reason globally the full image .
How deos it work ?
The system divides the input image into an S x S grid ( in this case S=7)
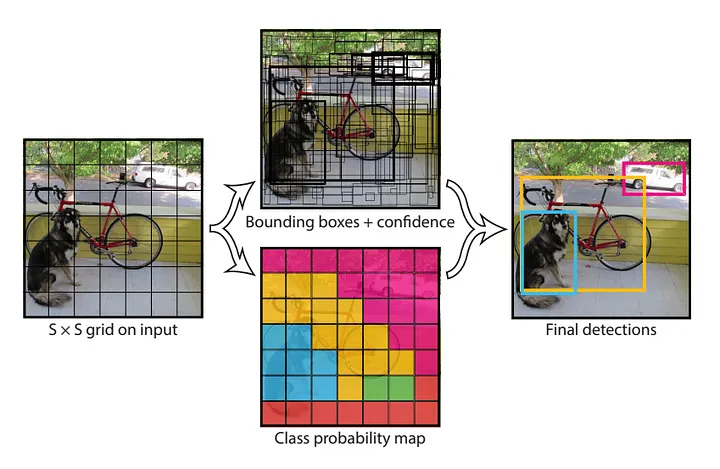 Each grid cell has B (B = 2) bounding boxes and their confidence score and class probability of all the labels C (C = 20). The confidence score reflect how confident the model is that box contains the object. For class probability, it’s the probability of that label being in that grid cell.
Each grid cell has B (B = 2) bounding boxes and their confidence score and class probability of all the labels C (C = 20). The confidence score reflect how confident the model is that box contains the object. For class probability, it’s the probability of that label being in that grid cell.
Deep Down Inside the network
Inferencing
The model is implemeneted as convolution neural network and evaluated on PASCAL VOC detection dataset . The model learns to predict S x S x (B ∗ 5 + C), where S = 7 , B = 2 and C = 20 (20 labels). For B, it consists of 5 predictions, x, y, w, h and c. So our final prediction is 7 x 7 x 30 tensor .
All the final tensor is just numbers , so we need to extract the real values .
First we extract the predictions probability of each class of each bounding boxes :
P(Class)=P(Class∣Object)×Confidence Score
where P(Class∣Object) is the predicted probability . Now we have 20 probabilities for each bounding boxes. Filter each probability by a threshold . Then for each class , we get the bounding box with highest probability . Now, across all the S x S grid cells we get multiples predictions of the same object, to remove the duplicate boxes, we apply Non-max suppression .
Training
 The system was pretrained on ImageNet 1000-class dataset. 20 convolution layers followed by averge-pooling layer and fully connected layer . The network trained for approximatly a week and acheived the top-5 accuracy of 88% on ImageNet 2012 validation set. The model then converted to perform detection , the input dimension was 228 x 228 x 3 in classification task and 448 x 448 x 3 in detection since it requires fine-grained visual information . For activation function , Leaky Rectified Linear activation was used .
The system was pretrained on ImageNet 1000-class dataset. 20 convolution layers followed by averge-pooling layer and fully connected layer . The network trained for approximatly a week and acheived the top-5 accuracy of 88% on ImageNet 2012 validation set. The model then converted to perform detection , the input dimension was 228 x 228 x 3 in classification task and 448 x 448 x 3 in detection since it requires fine-grained visual information . For activation function , Leaky Rectified Linear activation was used . For loss function, sum-square error was applied . It is easy to optimize, however it deos not perfectly align with the goal of maximizing the average precision. In every image many grid cells do not contain any object, this pushes the confidence score towards zero. This leads to model instability . To remedy this, we use two parameters, λcoord=5 to increase the loss of bounding box predictions. λnoobj = 0.5 to decrease the loss from confidence score for grid cells that don’t contain no objects.
For loss function, sum-square error was applied . It is easy to optimize, however it deos not perfectly align with the goal of maximizing the average precision. In every image many grid cells do not contain any object, this pushes the confidence score towards zero. This leads to model instability . To remedy this, we use two parameters, λcoord=5 to increase the loss of bounding box predictions. λnoobj = 0.5 to decrease the loss from confidence score for grid cells that don’t contain no objects.
Another issue is, sum-square error equally the error of large boxes and small boxes. Instead we want to make the small error of large boxes matter less then in small boxes. To address this, we use square root of bounding boxe width and height instead of raw width and height .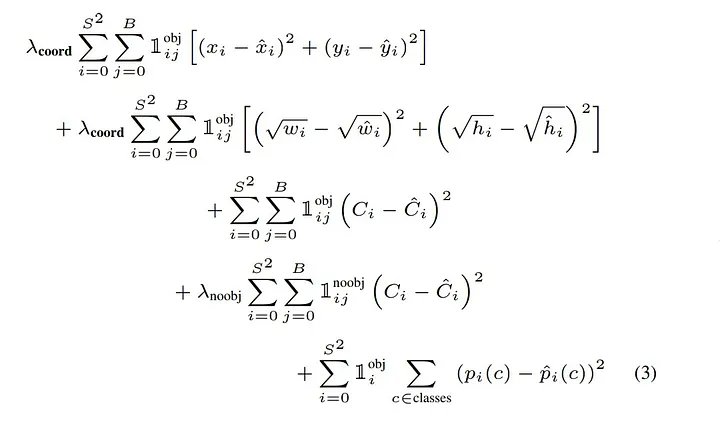 where 1obj i denotes if object appears in cell i , 1obj ij denotes that the _j_th bounding box if object appears cell i and 1noobj ij denotes that the _j_th bounding box if no object appears cell i .
where 1obj i denotes if object appears in cell i , 1obj ij denotes that the _j_th bounding box if object appears cell i and 1noobj ij denotes that the _j_th bounding box if no object appears cell i .
The network trained for 135 epochs on training and validation dataset from PASCAL VOC 2007 and
2012 with batch size of 64 and momentum of 0.9 and a decay 0.0005 . Dropout of 0.5 and extensive of data augmentation used to avoid overfitting .
Comparison to other Object Detection Systems
There are other top object detection systems that uses different approaches .
DPM(Deformable part methods) uses sliding window approach. DPM involves different pipelines, extracting features, classify region, predict bounding boxes for high scoring region, etc. In YOLO all this can be summaries in a single convolution network making it more efficient? fast and easy to optimized then DPM .
R-CNN, uses region proposal to find objects in the image, run Selective Search to generate bounding boxes, convolution network to extract the features , SVM scores the boxes, a linear model adjust the bounding boxes, etc . Each stage need to be trained separately and the resulting system is very slow , taking more then 40 seconds per image at test time .
YOLO and R-CNN share some similarity, each grid cell proposes potential bounding boxes and score those boxes using convolution network . However in YOLO, there is only 98 bounding boxes which is far from Selective Search that proposes 2000 bounding boxes, in addition to the rest components of R-CNN is combined individually in a single convolution network in YOLO .
Expirements
Comparison to Other Real-Time System
The detector systems below have trained on PASCAL dataset . The table below compares the performance and speed .
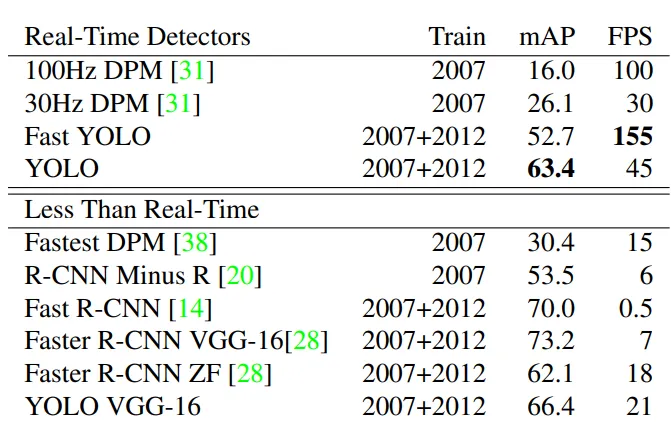 Sadeghi et al is produces DPM and it is the only detection system that runs in real-time of 30 frames per second with 16% mAp on 100Hz, 100 fps and 26.1% on 30Hz . Fast YOLO is the fastest model on PASCAL, reaching 155 fps and 52.7% on mAP. Fast R-CNN takes a significant accuracy of 73.2% mAP while still fall short of real-time .
Sadeghi et al is produces DPM and it is the only detection system that runs in real-time of 30 frames per second with 16% mAp on 100Hz, 100 fps and 26.1% on 30Hz . Fast YOLO is the fastest model on PASCAL, reaching 155 fps and 52.7% on mAP. Fast R-CNN takes a significant accuracy of 73.2% mAP while still fall short of real-time .
VOC 2007 Error Analysis
Since Fast R-CNN is the only detector that made 70% mAP on PASCAL , we will compare it to YOLO .
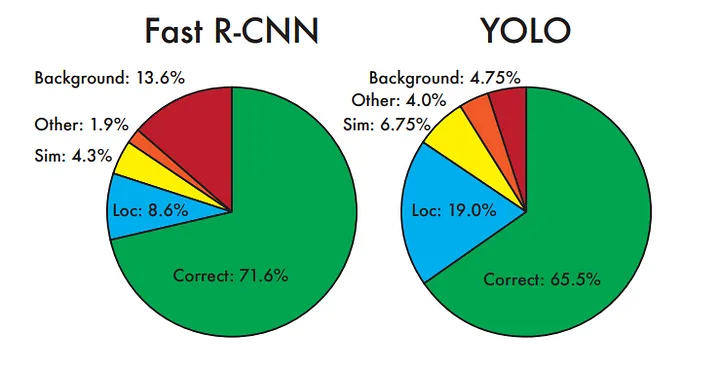 As you can see in the chart above, Fast R-CNN makes more correct prediction of 71.6% then YOLO. However Fast R-CNN is likely to predict false positive(background) as it is 13.6% of its prediction. YOLO on other hand struggles to localize the object correctly .
As you can see in the chart above, Fast R-CNN makes more correct prediction of 71.6% then YOLO. However Fast R-CNN is likely to predict false positive(background) as it is 13.6% of its prediction. YOLO on other hand struggles to localize the object correctly .
Combining Fast R-CNN and YOLO
YOLO makes less background errors and with Fast R-CNN predict the correct localization, if we combine the two, we get a significant performance .
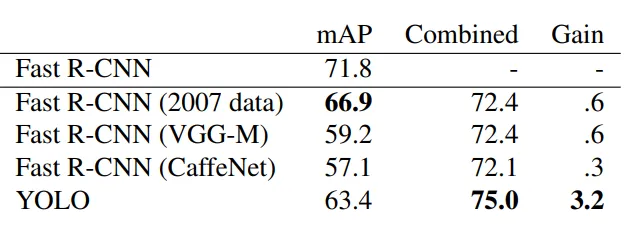 The best combination is Fast R-CNN and YOLO, you can see the mAP increase by 3.2% to 75% . Other combinations with other version of Fast R-CNN produce a small increase in mAP between 0.3% and 0.6% which makes the ideal one is Fast R-CNN with YOLO. However, this combination doesn’t benefit from the speed of YOLO. Each model is runining seperatly and then combine the results and this doesn’t add any signifant computational time compared to Fast R-CNN .
The best combination is Fast R-CNN and YOLO, you can see the mAP increase by 3.2% to 75% . Other combinations with other version of Fast R-CNN produce a small increase in mAP between 0.3% and 0.6% which makes the ideal one is Fast R-CNN with YOLO. However, this combination doesn’t benefit from the speed of YOLO. Each model is runining seperatly and then combine the results and this doesn’t add any signifant computational time compared to Fast R-CNN .
VOC 2012 results
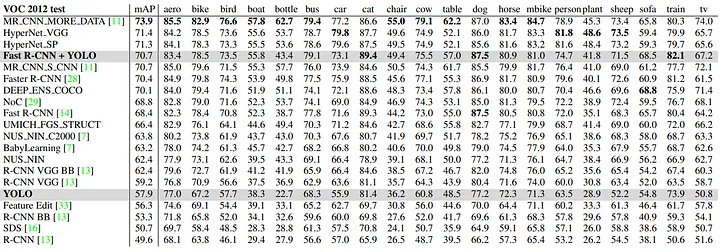 YOLO scores 57.9% mAP on VOC 2012 results . It is lower then the current state-of-the-art. Fast R-CNN + YOLO is one of the highest performance in the leaderboard by taking the 4th spot .
YOLO scores 57.9% mAP on VOC 2012 results . It is lower then the current state-of-the-art. Fast R-CNN + YOLO is one of the highest performance in the leaderboard by taking the 4th spot .
YOLO is the only real-time detection in the leaderboard
Generalizability: Person Detection in Artwork
We compare YOLO to other detection systems on two dataset of person, People-Art and Picasso .
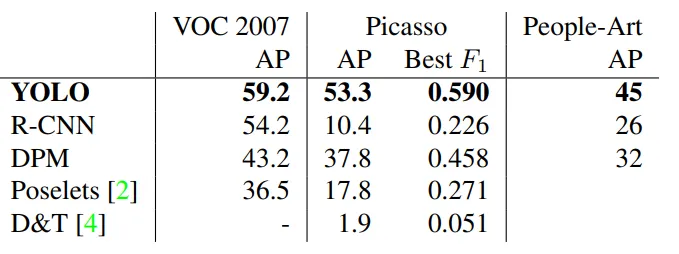 YOLO has the highest AP in VOC 2007 , and it is decreasing when applied to artwork such as Picasso and People-Art, thus YOLO can still predict well on artwork compared to other systems. R-CNN drops significantly when applied to artwork. The reason behind this, is R-CNN uses region proposal which is tuned for natural images .
YOLO has the highest AP in VOC 2007 , and it is decreasing when applied to artwork such as Picasso and People-Art, thus YOLO can still predict well on artwork compared to other systems. R-CNN drops significantly when applied to artwork. The reason behind this, is R-CNN uses region proposal which is tuned for natural images .
Conclusion
YOLO, a unified model for object detection. Fast, accurate and can perform well on different uses cases, making it one of the best object detection out their .